The following step-by-step installation guide will get you through the entire process from downloading the software to configuring the server with ease. In this article, we will explain how to install Apache Hadoop on Ubuntu 22.04 LTS system. This can be also used for other Ubuntu versions.
Step 1: Install Java Development Kit
Java is a necessary component of Apache Hadoop, so you need to download and install a Java Development Kit on all the nodes in your network where Hadoop will be installed. You can either download the JRE or JDK. If you’re only looking to run Hadoop, then JRE is sufficient, but if you want to create applications that run on Hadoop, then you’ll need to install the JDK. The latest version of Java that Hadoop supports is Java 8 and 11. You can verify this on Apache’s website and download the relevant version of Java depending on your OS.
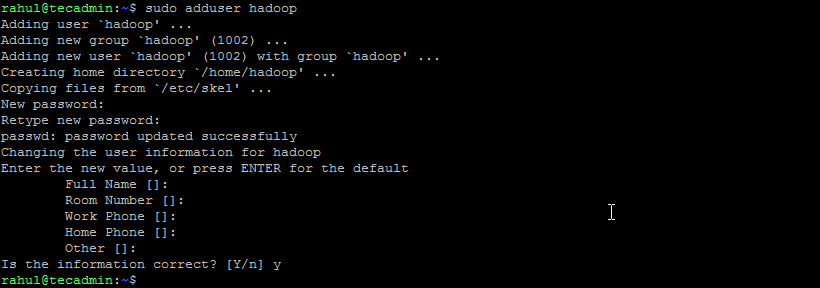
Step 2: Create User for Hadoop
All the Hadoop components will run as the user that you create for Apache Hadoop, and the user will also be used for logging in to Hadoop’s web interface. You can create a new user account with the “sudo” command or you can create a user account with “root” permissions. The user account with root permissions is more secure but might not be as convenient for users who are not familiar with the command line.
Step 3: Install Hadoop on Ubuntu
Once you’ve installed Java, you can download Apache Hadoop and all its related components, including Hive, Pig, Sqoop, etc. You can find the latest version on the official Hadoop’s download page. Make sure to download the binary archive (not the source).
Step 4: Configuring Hadoop
Next is to configure Hadoop configuration files available under etc directory.
Save the file and close it. Save the file and close it.
Step 5: Start Hadoop Cluster
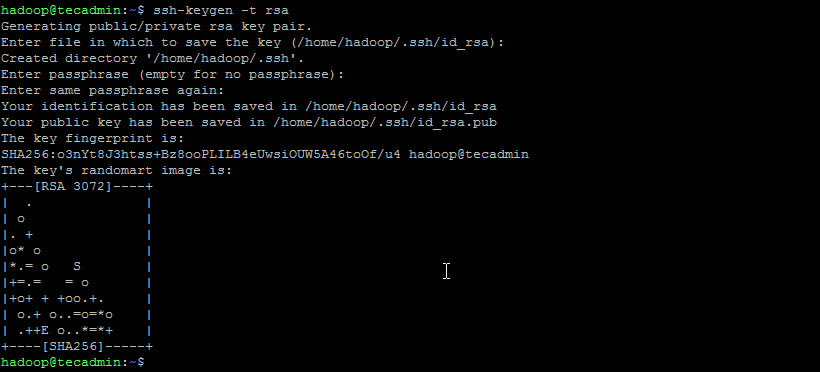
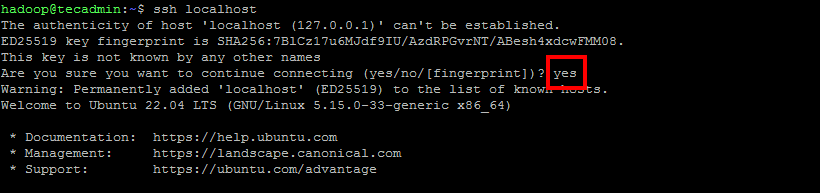
Before starting the Hadoop cluster. You will need to format the Namenode as a hadoop user.
Save and close the file.
Save and close the file.
Save and close the file.
Save the file and close it.
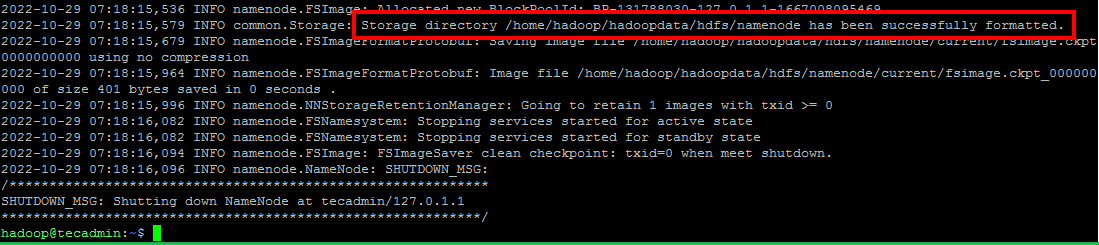
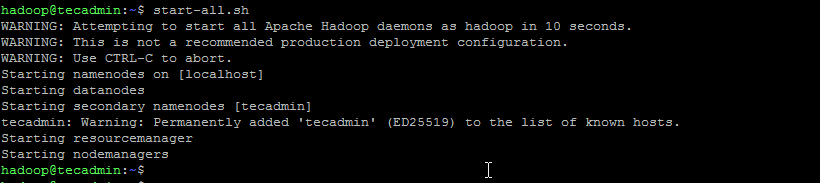
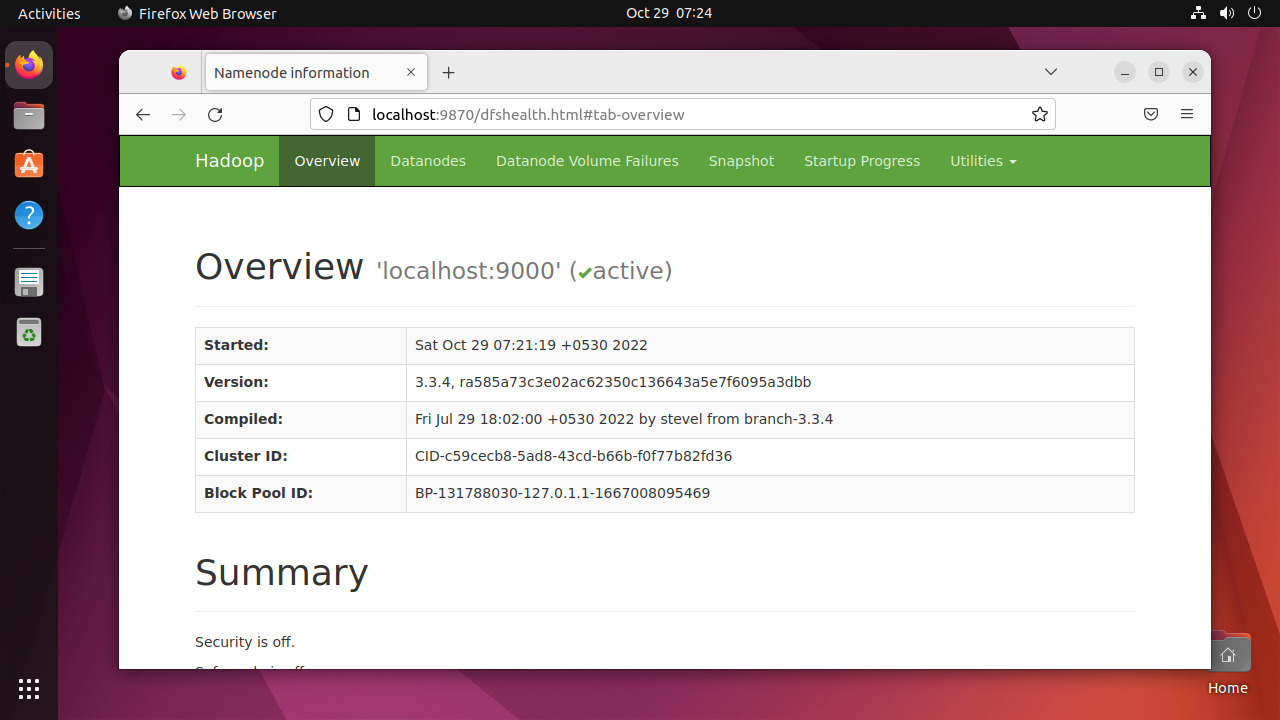
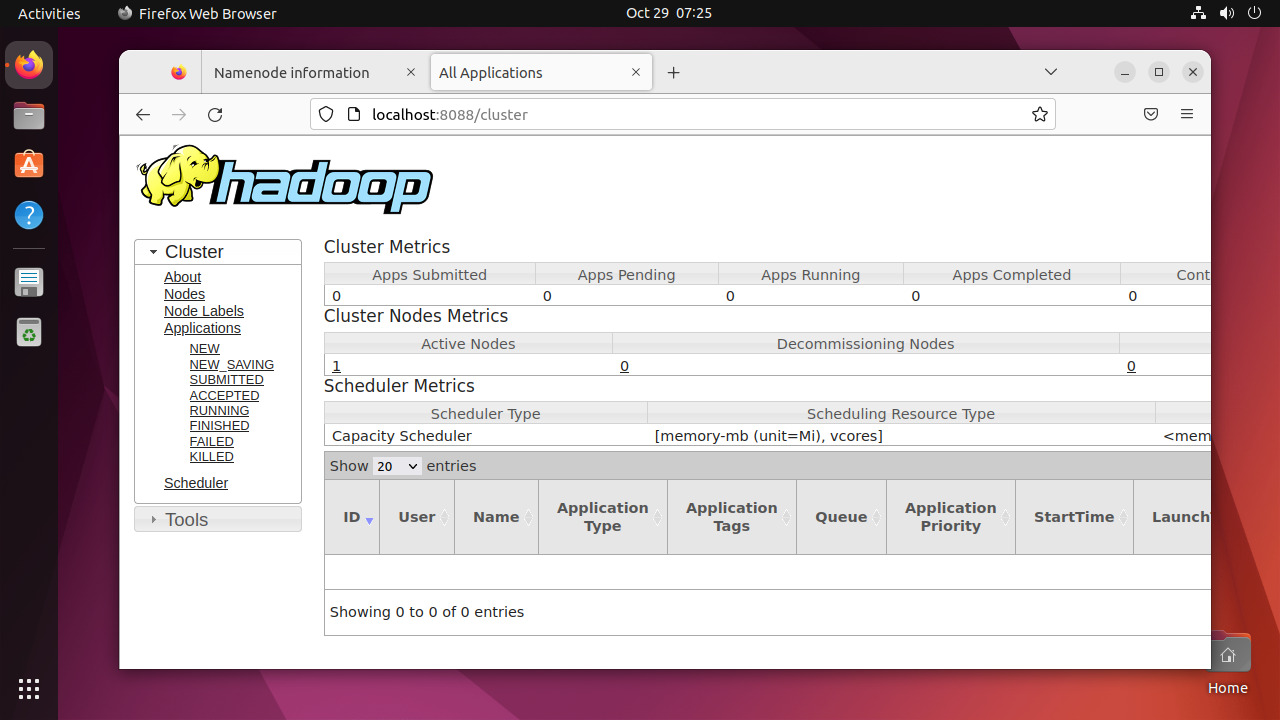
Run the following command to format the Hadoop Namenode:hdfs namenode -format Once the namenode directory is successfully formatted with hdfs file system, you will see the message “Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted“.Format namenode Then start the Hadoop cluster with the following command.start-all.sh Start hadoop services Once all the services started, you can access the Hadoop at: http://localhost:9870 And the Hadoop application page is available at http://localhost:8088
Conclusion
Installing Apache Hadoop on Ubuntu can be a tricky task for newbies, especially if they only follow the instructions in the documentation. Thankfully, this article provides a step-by-step guide that will help you install Apache Hadoop on Ubuntu with ease. All you have to do is follow the instructions listed in this article, and you can be sure that your Hadoop installation will be up and running in no time. Format namenode